
Summary
In October 2020, The World Economic Forum published the report “The Future of Jobs”. This report has deep insights on technological adoption in the next five years, and it maps the jobs and skills of the future including a deep dive into Data and AI Skills. The report shows that technological adoption continues expanding, while skills availability remains the #1 barrier to that adoption. Businesses and governments around the world are investing significantly in upskilling and reskilling programs, with a significant percentage of that investment going towards transitions into Data and AI Jobs. Demand for Data Analysts, Data Scientists, and AI Specialists is high, but the skills gap that needs to be addressed to successfully transition into those roles is large.
Some of the key findings:
- Skills gaps continue to be high. This includes skills like critical thinking, analysis, problem-solving, and skills in self-management such as active learning, resilience, stress tolerance and flexibility. On average, companies estimate that around 40% of workers will require reskilling of six months or less and 94% of business leaders report that they expect employees to pick up new skills on the job, a sharp uptake from 65% in 2018.
- Online learning is on the rise. There has been a four-fold increase in the numbers of individuals seeking out opportunities for learning online through their own initiative, a five-fold increase in employer provision of online learning opportunities to their workers and a nine-fold enrollment increase for learners accessing online learning through government programs
- The window of opportunity to reskill and upskill workers has become shorter. The share of core skills that will change in the next five years is 40%, and 50% of all employees will need reskilling
- The large majority of employers recognize the value of human capital investment. 66% of employers surveyed expect to get a return on investment in upskilling and reskilling within one year. Employers expect to offer reskilling and upskilling to over 70% of their employees, but employee engagement into those courses is lagging, with only 42% of employees taking up employer-supported reskilling and upskilling opportunities.
Over the past decade, a set of ground-breaking, emerging technologies have signaled the start of the Fourth Industrial Revolution. By 2025, the capabilities of machines and algorithms will be more broadly employed than in previous years, and the work hours performed by machines will match the time spent working by human beings. This augmentation of work will disrupt the employment prospects of workers across a broad range of industries and geographies, and we will see job growth in the ‘jobs of tomorrow’— such as roles at the forefront of the data and AI economy, as well as new roles in engineering, cloud computing and product development.
Technological Adoption
The past two years have seen a clear acceleration in the adoption of new technologies. Cloud computing, big data and e-commerce remain high priorities, following a trend established in previous years. However, there has also been a significant rise in interest in encryption, and a significant increase in the number of firms expecting to adopt robots and artificial intelligence. These new technologies are set to drive future growth across industries, as well as to increase the demand for new job roles and skill sets. Figure 1 shows technologies likely to be adopted by 2025 (by share of companies surveyed).

By 2025 the average estimated time spent by humans and machines at work will be at parity based on today’s tasks. Algorithms and machines will be primarily focused on the tasks of information and data processing and retrieval, administrative tasks and some aspects of traditional manual labor. The tasks where humans are expected to retain their comparative advantage include managing, advising, decision-making, reasoning, communicating and interacting.
Emerging Jobs
Similar to the last survey in 2018, the leading positions in growing demand are roles such as Data Analysts and Scientists, AI and Machine Learning Specialists, Robotics Engineers, Software and Application developers as well as Digital Transformation Specialists. However, job roles such as Process Automation Specialists, Information Security Analysts and Internet of Things Specialists are newly emerging among a cohort of roles which are seeing growing demand from employers. The emergence of these roles reflects the acceleration of automation as well as the resurgence of cybersecurity risks. Figure 2 shows the top 20 job roles in increasing demand across industries, with Data Analysts, Data Scientists, and AI Specialists ranked with the highest demand overall.

These emerging jobs have been organized in clusters, and this report presents a unique analysis which examines key learnings gleaned from job transitions into those emerging clusters using LinkedIn and Coursera data gathered over the past five years. The main clusters are: Data and AI, Cloud Computing, Engineering, Content Production, Marketing, People and Culture, and Product Development and Sales. Figure 3 shows Data and AI roles organized according to the scale of each opportunity within the cluster.


Figure 3 – Data and AI Job Cluster
Emerging Skills
The ability of global companies to harness the growth potential of new technological adoption is limited by skills shortages. Figure 4 shows that skills gaps in the local markets and inability to attract the right talent remain among the leading barriers to the adoption of new technologies.
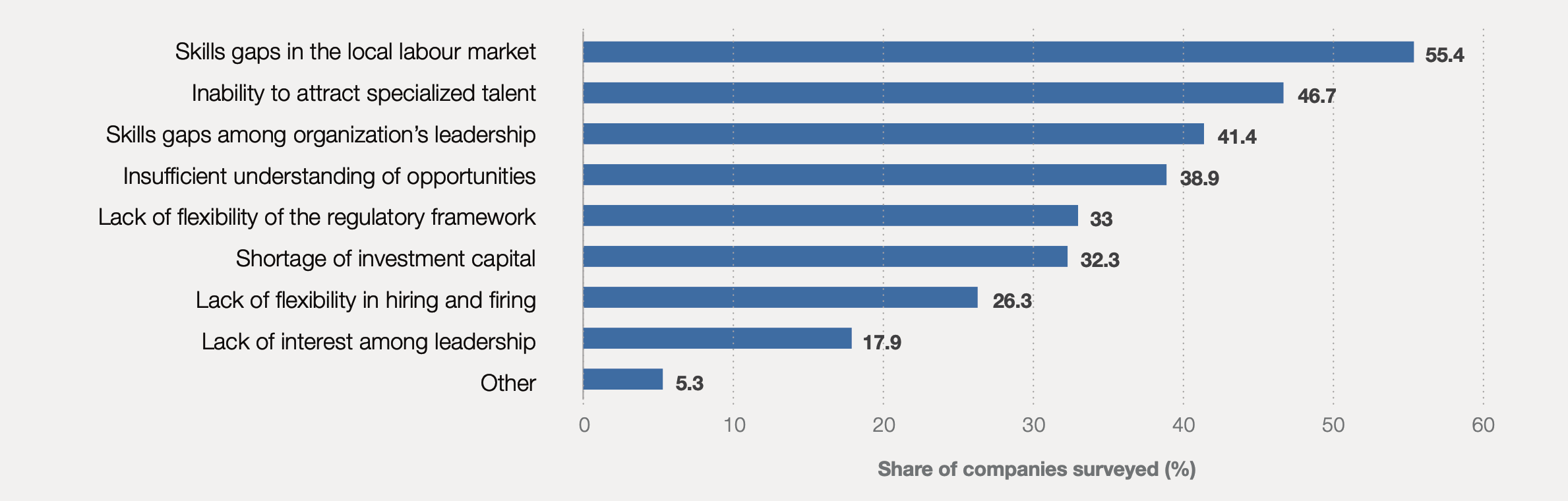
Skill shortages are more acute in emerging professions. Business leaders consistently cite difficulties when hiring for Data Analysts and Scientists, AI and Machine Learning Specialists as well as Software and Application Developers.
To address skills shortages, companies are investing in upskilling and reskilling programs. However, employee engagement into those courses is lagging, with only 42% of employees taking up employer-supported reskilling and upskilling opportunities. There are however significant challenges in the amount of skills that need to be developed especially for emerging roles in Data Science and Artificial Intelligence. Figure 5 illustrates the skills gap that needs to be closed for individuals to transition into these roles, with Artificial Intelligence, NLP, Data Science and Signal Processing representing the largest amount of skills needed to be developed for a successful transition.
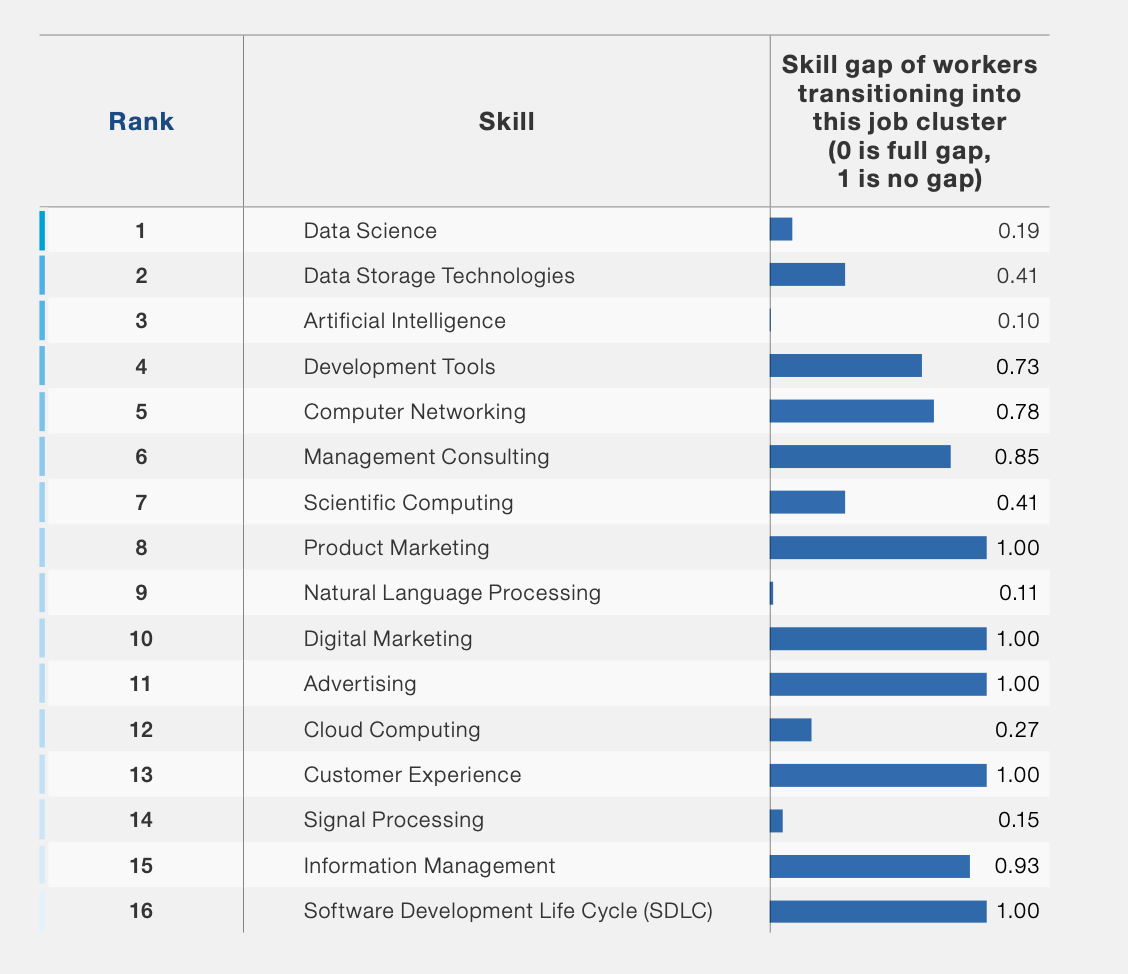
Furthermore, the report uses data from Coursera learners to estimate the distance from the optimal level of mastery for learners targeting to transition into Data and AI, and quantifies the days of learning needed for the average worker to gain that level of mastery. (Figure 6).

Mastery score is the score attained by those in the top 80% on an assessment for that skill. Mastery gap is measured as a percentage representing the score among those looking to transition to the occupation as a share of the score among those already in the occupation.
In conclusion, technological adoption continues expanding, and skills availability remains the #1 barrier to that adoption. Businesses and governments around the world are investing significantly in upskilling and reskilling programs, with a significant percentage of that investment going towards transitions into Data and AI Jobs. Demand for Data Analysts, Data Scientists, and AI Specialists is high, but the skills gap that needs to be addressed to successfully transition into those roles is large.




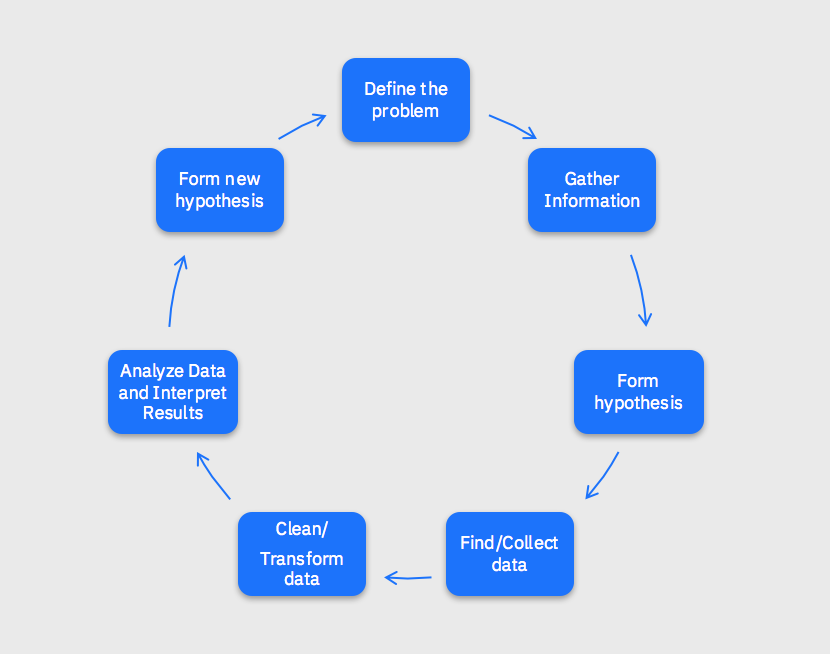
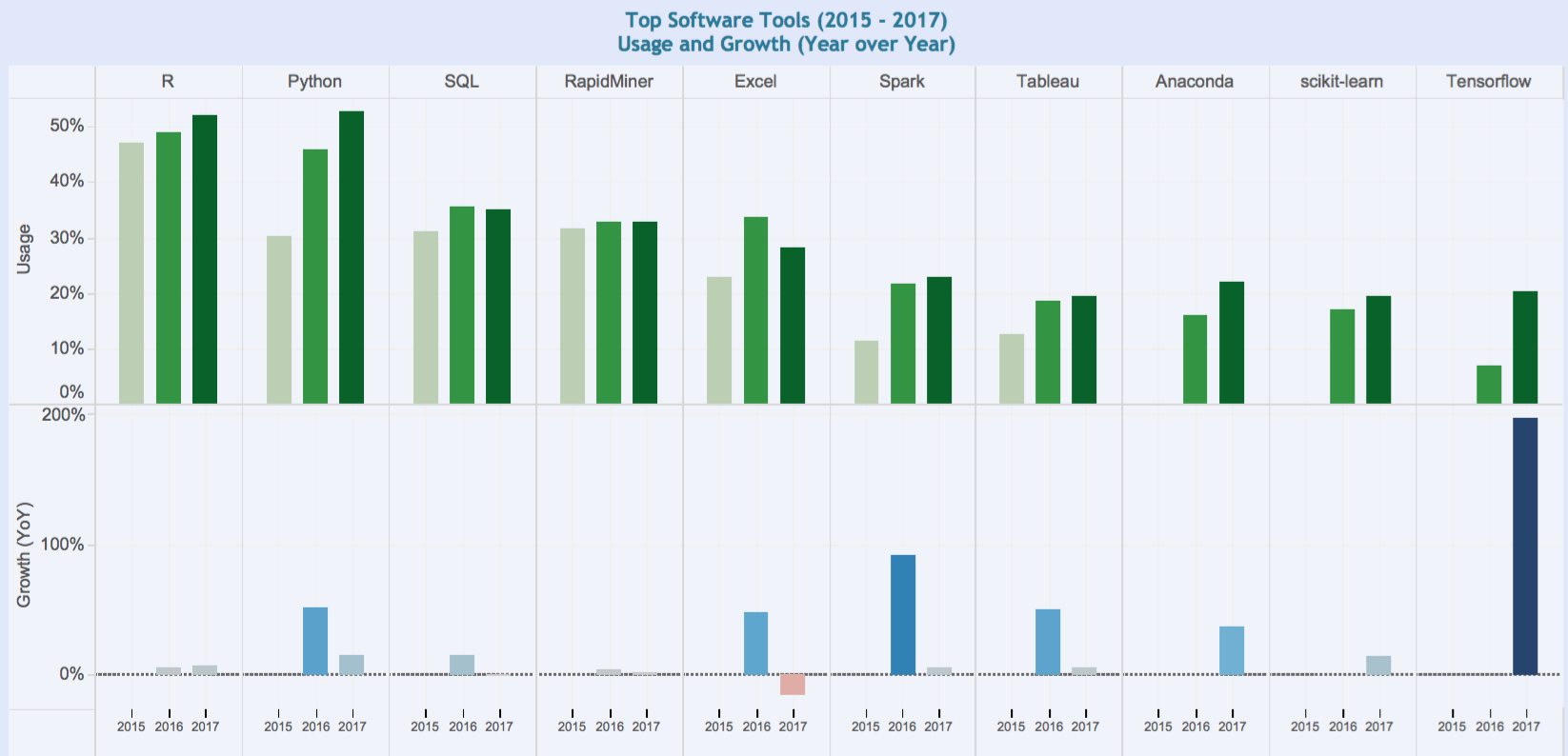

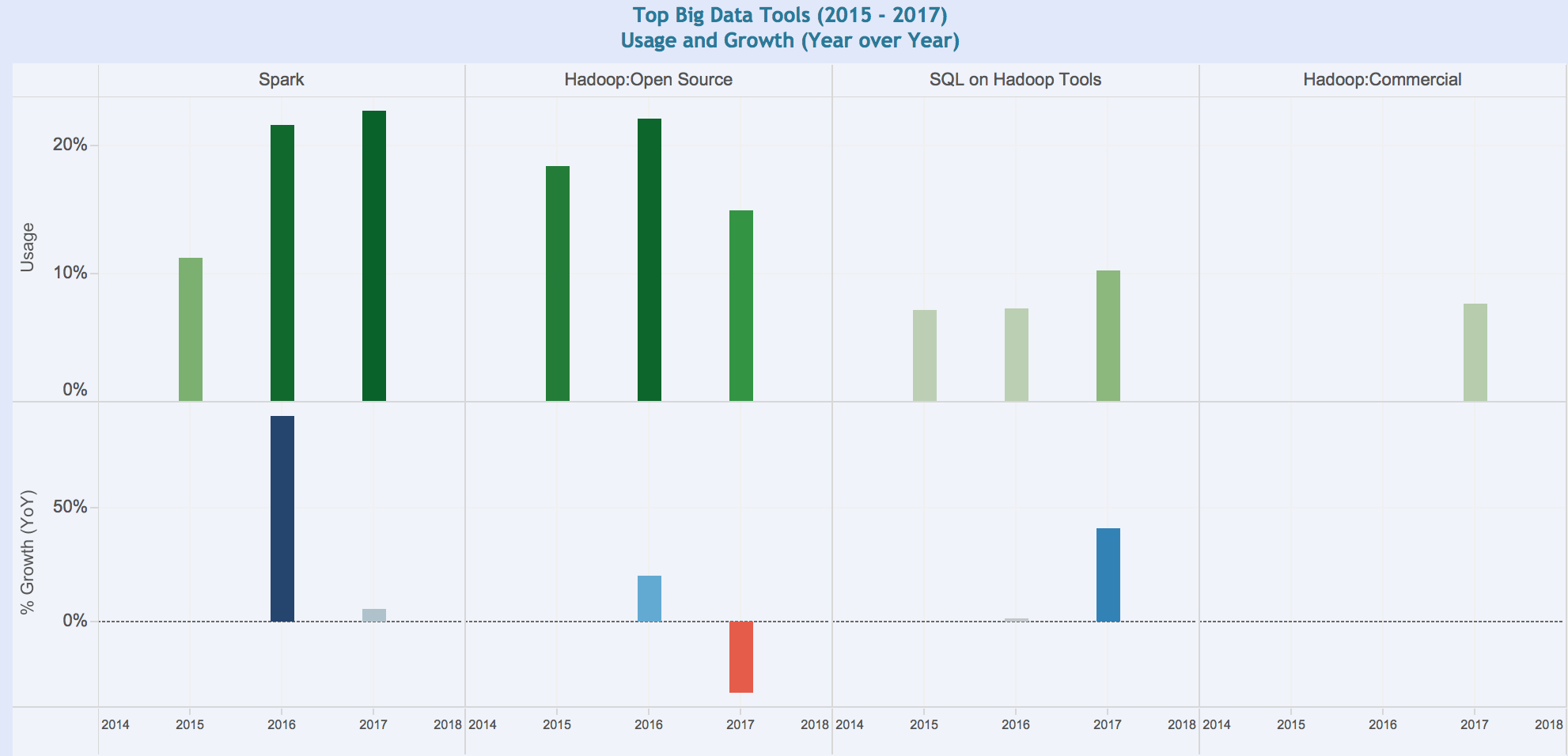


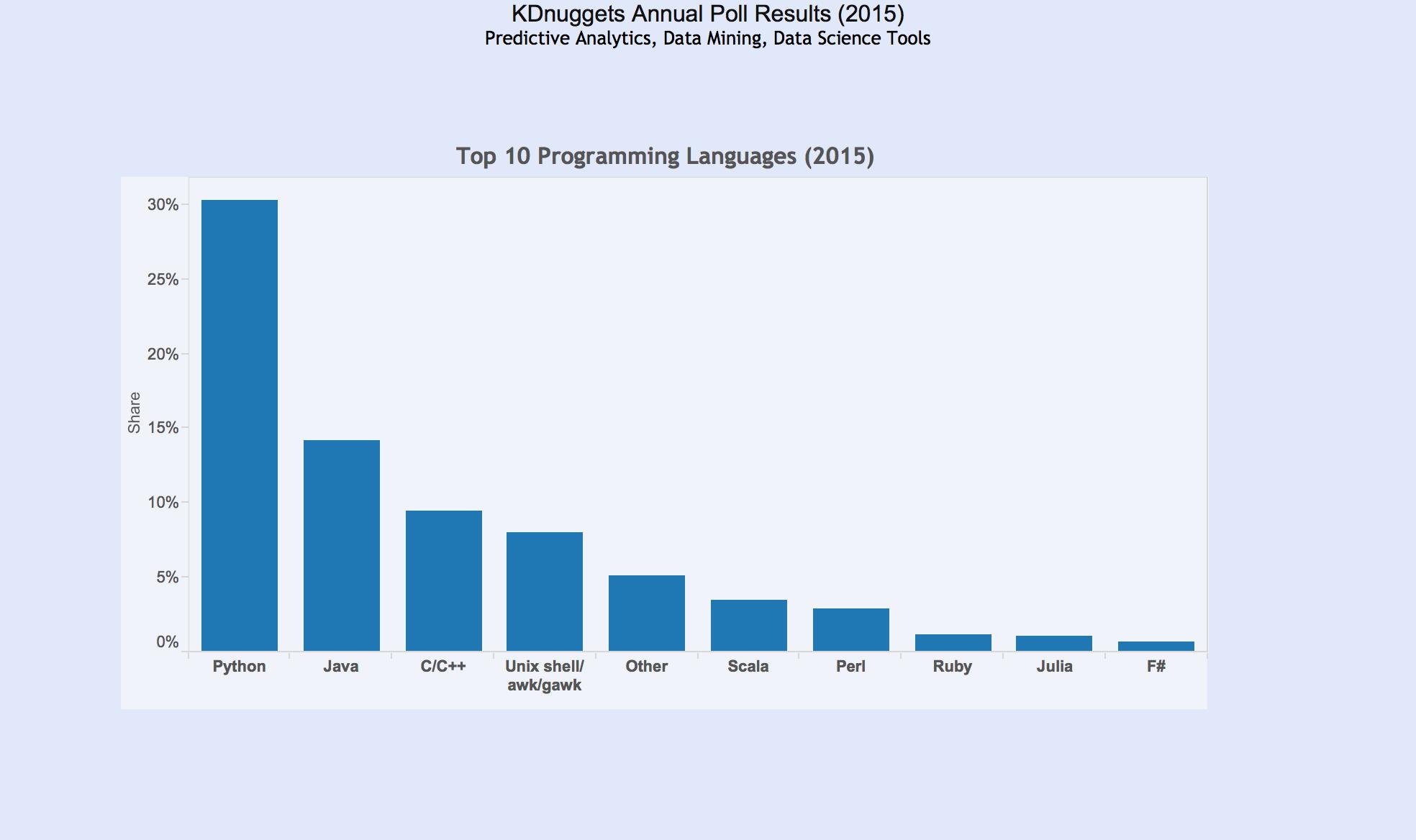


You must be logged in to post a comment.