

Data Science is an emerging field, but it is definitely not a new field. Yet, many people still struggle to define Data Science as a field, and more importantly, struggle to define the set of skills that collectively define a “Data Scientist”.
What is data science?
Data Science is a cross-disciplinary set of skills found at the intersection of statistics, computer programming, and domain expertise. Perhaps one of the simplest definitions is illustrated by Drew Conway’s Data Science Venn Diagram (Figure 1), first published on his blog in September 2010. Discussions about this field, however, go as far back as 50 years. If you are interested in learning more about the history of the Data Science field, you can read it in the 50 Years of Data Science paper written by David Donoho.
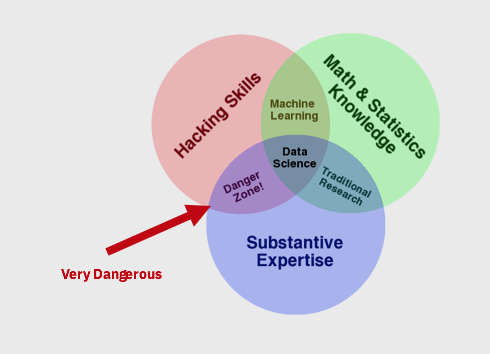
Figure 1 – Drew Conway’s Data Science Venn Diagram
The bottom line is that Data science comprises three distinct and overlapping areas: a set of math and statistics knowledge which provides the ability to understand and model datasets, a set of computer programming/hacking skills to leverage algorithms that can analyze and visualize data, and the domain expertise needed to ask the right questions, and put the answers in the right context.
It is important to call out attention to the “Danger Zone” above, as there is nothing more dangerous than aspiring Data Scientists who do not have the appropriate math and statistical foundation to model data.
What skills define the role of Data Scientists?
A Data Scientist is not a just a computer programmer, or just a statistician, or just a business analyst. In order to be a data scientist, individuals need to acquire knowledge from all these disciplines, and at the minimum develop skills in the following areas:
1.Probability, Statistics, and Math foundation. This includes probability theory, sampling, probability distributions, descriptive statistics (measures of central tendency and dispersion, etc.), inferential statistics (correlations, regressions, central limit theory, confidence intervals, development and testing of hypothesis, etc.) and linear algebra (working with vectors and matrices, eigenvectors, eigenvalues, etc.)
2.Computer Programming. Throughout the years, SAS has probably been the most commonly used programming language for Data Science, but adoption of Open Source Languages Python and R has increased significantly. If you are starting today to acquire data science skills, my recommendation would be to focus on Python. Looking at worldwide searches on Google for “R Data Science” and comparing them to “Python Data Science”, the trends are clear (Figure 2). Interest in Python has surpassed R, and continue on a positive trend. This makes sense given that python allows you to create models and also to deploy them as part of an enterprise application, so within the same platform data scientists and app developers can work together to build and deploy end to end models. R while easier in some cases for modeling purposes, was not designed as a multi-purpose programming language.
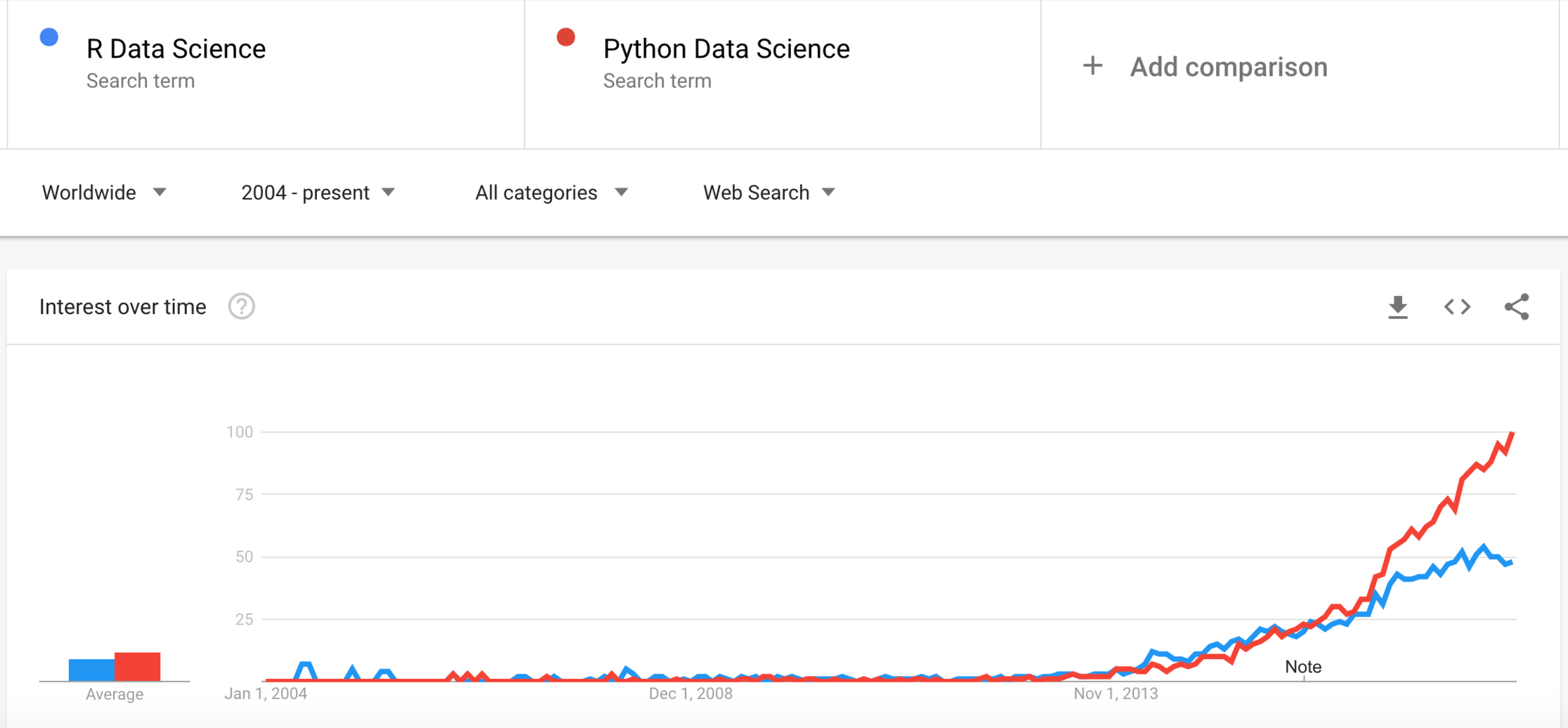
Figure 2 Worldwide searches for “R Data Science” vs. “Python Data Science”. Google Trends (June 2018)
3. Data Science Foundation. This involves learning what data science is and its value in specific use cases. It also involves learning how to formulate problems as research questions with associated hypotheses, and applying the scientific method to business problems. Data Science is an iterative process so it is critical to have a solid understanding of the methodologies used in the execution of this iterative process (Define the problem, Gather Information, Form hypothesis, Find/Collect data, Clean/Transform data, Analyze Data and Interpret Results, Form new hypothesis)
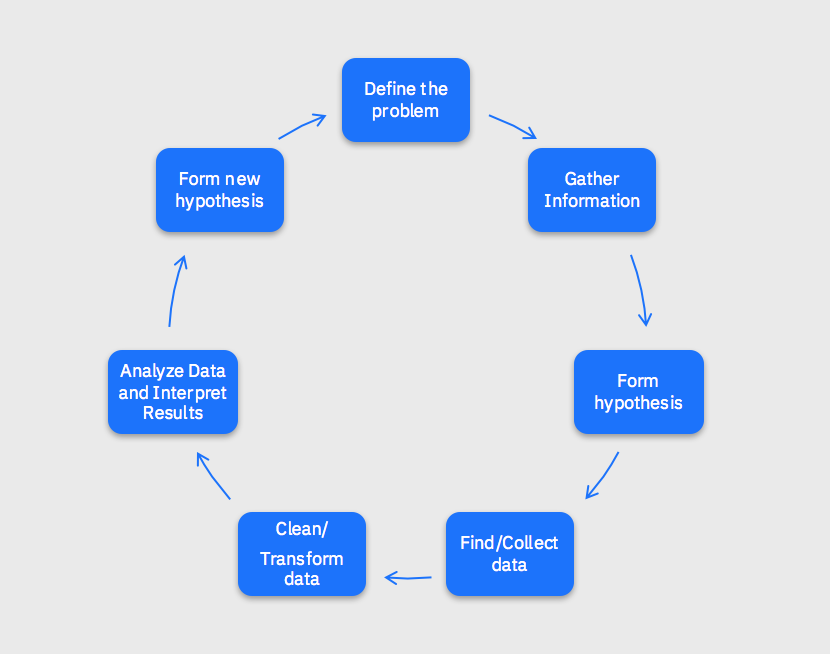
Figure 3 Data Science Iterative Cycle
4. Data Preparation/Data Wrangling. Data is by definition dirty. And before data can be analyzed and modeled, it needs to be collected, integrated, cleaned, manipulated and transformed. Although this is the domain of “Data Engineers”, Data Scientists should also have a solid understand of how to construct usable, clean datasets
5. Model Building. This is the core of the data science execution, where different algorithms are used to train models with data( structured and unstructured) and the best algorithm is selected. At this stage, data scientists need to make basic decisions around the data such as how to deal with missing values, outliers, unbalanced data, multicollinearity, etc. They need to have solid knowledge of feature selection techniques (which data to include in the analysis), and be proficient in the use of techniques for dimensionality reduction such as principal component analysis. Data scientists will be able to test different supervised and unsupervised algorithms such as regressions, logistic regressions, decision trees, boosting, random forest, Support Vector Machines, association rules, classification, clustering, neural networks, time series, survival analysis, etc. Once different algorithms are tested, the “best” algorithm is selected using different model accuracy metrics. Data scientists should also be skilled in data visualization techniques, and should have solid communication skills to properly share the results of the analysis and the recommendations with nontechnical audiences.
6. Model deployment. A very important part of building models is to understand how to deploy those models for consumption from a data application. While this is typically the domain of machine learning engineers and application developers, data scientists should be familiar with the different methods to deploy models.
7. Big Data Foundation. A lot of organizations have deployed big data infrastructure such as Hadoop and Spark. It is important for data scientists to know how to work with these environments.
8. Soft Skills. Successful data scientists should also have the following soft skills:
a. Ability to work in teams. Because of the inter-disciplinary nature of this field, it is by definition a team sport. While every data scientist on a team will need a good foundation on all skills defined above, the depth of skills will vary among them. This is not a field for individualistic stars, but a field for natural team players.
b. Communication Skills. Data scientists need to be able to explain the results of their analysis and the implications of those results in nontechnical terms. The best analysis can go to waste is not properly communicated.
Last but not least, it is important to remember that the most important characteristic of great data scientists is CURIOSITY. Data Scientists should be relentless in their search for the best data and the best algorithm, and should also be lifelong learners as this field is advancing very rapidly.
In summary, if you are interested in the Data Science field, or if you are exploring ways to develop your skills, make sure that you are addressing all these areas, and especially make sure not to end up in the danger zone having programming skills and domain knowledge but lacking the math and statistics foundation needed to model data correctly.
